
😊 About Me
I am Jiaming Liang. I am a first-year Ph.D student under the supervision of Prof. Hongmin Cai at South China University of Technology. Before this, I completed my Master’s degree at Guangzhou University, and I had the honor of being mentored by Prof. Qiong Wang and Assoc. Prof. Yan Pang
My research interests are primarily focused on medical image analysis and biomedical computing.
🔥 News
- 2026.3.29: 🎉🎉 A paper (Waveformer) has been accepted for IEEE Journal of Biomedical and Health Informatics (JBHI)!
- 2025.11.11: 🎉🎉 A paper (MM-UNet) has been accepted for IEEE International Conference on Bioinformatics and Biomedicine (BIBM)!
- 2025.08.25: 🎉🎉 A paper (Slim UNETRV2) has been accepted for IEEE Transactions on Medical Imaging!
💫 Representative
📝 Publications (by date)
-
Liming Liang, Ting Kang, Yulin Li, Jiaming Liang, et al. “Waveformer: Dual-Branch Adaptive Network with Wavelet-Guided Cross-Context Decoding for Colorectal Polyp Segmentation.” IEEE journal of biomedical and health informatics.
-
Jiawen Liu, Jiaming Liang (co-author), et al. “MM-UNet: Morph Mamba U-shaped Convolutional Networks for Retinal Vessel Segmentation.” IEEE International Conference on Bioinformatics and Biomedicine (BIBM).
-
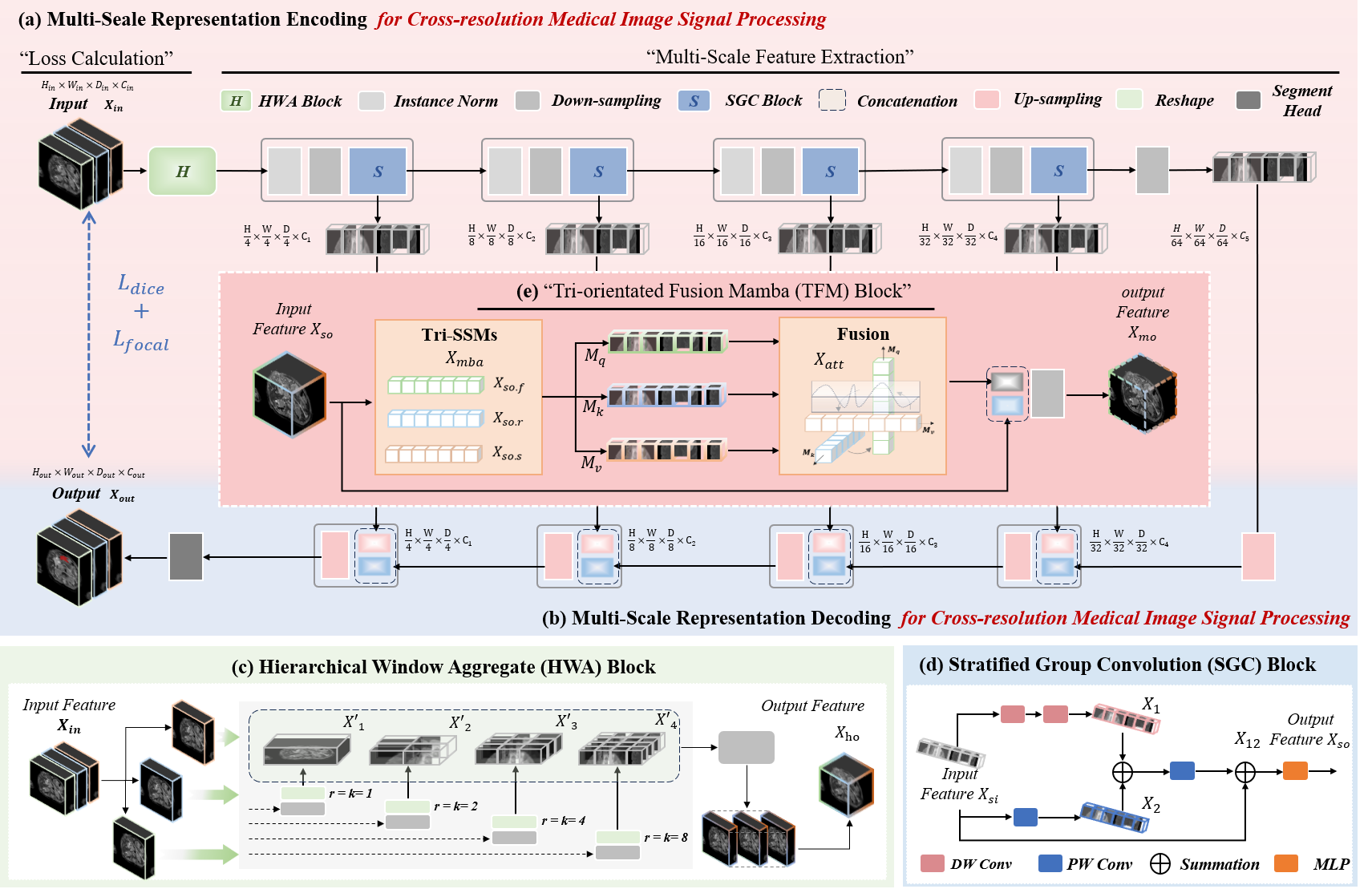
Jiaming Liang, et al. “Hwa-unetr: Hierarchical window aggregate unetr for 3d multimodal gastric lesion segmentation.” International Conference on Medical Image Computing and Computer-Assisted Intervention. Cham: Springer Nature Switzerland, 2025.
-
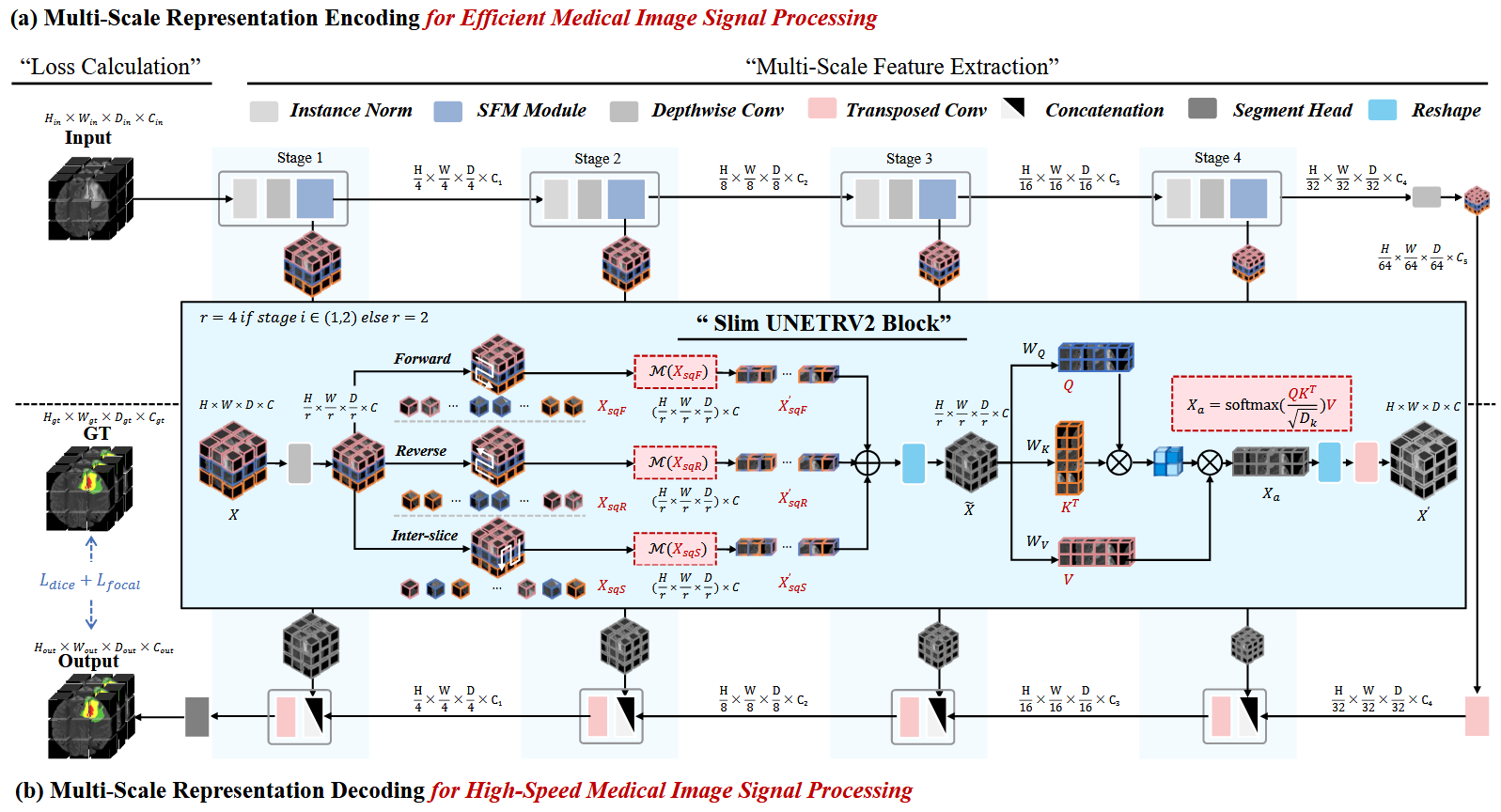
Yan Pang (Adviser), Jiaming Liang, et al. “Slim unetrv2: 3d image segmentation for resource-limited medical portable devices.” IEEE Transactions on Medical Imaging (2025).
-
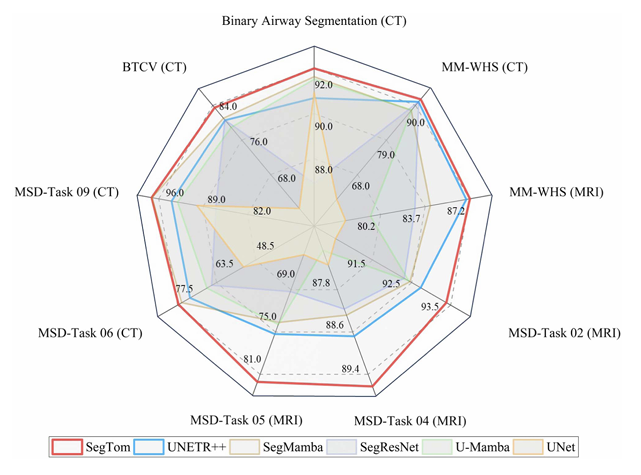
Yan Pang, Yunhao Li, Jiaming Liang, et al. “SegTom: a 3D volumetric medical image segmentation framework for thoracoabdominal multi-organ anatomical structures.” IEEE Journal of Biomedical and Health Informatics (2025).
-
Yan Pang, Yunhao Li, Teng Huang, Jiaming Liang, et al. “Efficient breast lesion segmentation from ultrasound videos across multiple source-limited platforms.” IEEE Journal of Biomedical and Health Informatics (2025).
-
Yan Pang, Yunhao Li, Teng Huang, Jiaming Liang, et al. “Online self-distillation and self-modeling for 3D brain tumor segmentation.” IEEE Journal of Biomedical and Health Informatics 29.12 (2025): 8965-8975.
-
Jiaming Liang, et al. “Comprehensive transformer integration network (ctin): Advancing endoscopic disease segmentation with hybrid transformer architecture.” *Chinese Conference on Pattern Recognition and Computer Vision (PRCV). Singapore: Springer Nature Singapore, 2024**.
-
Teng Huang, Yile Hong, Yan Pang, Jiaming Liang, et al. “AdaptFormer: An adaptive hierarchical semantic approach for change detection on remote sensing images.” IEEE Transactions on Instrumentation and Measurement 73 (2024): 1-12*.
-
Yan Pang (Adviser), Jiaming Liang, et al. “Slim UNETR: Scale hybrid transformers to efficient 3D medical image segmentation under limited computational resources.” IEEE transactions on medical imaging 43.3 (2023): 994-1005.
-
Jiaming Liang, et al. “GanNoise: Defending against black-box membership inference attacks by countering noise generation.” 2023 International Conference on Data Security and Privacy Protection (DSPP). IEEE, 2023.
-
Bo Wei, Teng Huang, Xi Zhang, Jiaming Liang, et al. “CAM-PC: A novel method for camouflaging point clouds to counter adversarial deception in remote sensing.” IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing 17 (2023): 56-67.
-
Jiaming Liang, et al. “Agilenet: A rapid and efficient breast lesion segmentation method for medical image analysis.” Chinese Conference on Pattern Recognition and Computer Vision (PRCV). Singapore: Springer Nature Singapore, 2023.
-
Teng Huang, Weiqing Kong, Jiaming Liang, et al. “Lightweight Multispectral Skeleton and Multi-stream Graph Attention Networks for Enhanced Action Prediction with Multiple Modalities.” Chinese Conference on Pattern Recognition and Computer Vision (PRCV). Singapore: Springer Nature Singapore, 2023.
-
Hongyang Yan, Anli Yan, Li Hu, Jiaming Liang, Haibo Hu. “MTL-leak: Privacy risk assessment in multi-task learning.” IEEE Transactions on Dependable and Secure Computing 21.1 (2023): 204-215.