基于自定义数据集的Caffe模型生成

首先,整个的工程目录大概是这样的:每个文件对应的功能会在后面的文章中介绍,现在可以先不急于创建整个工程目录。
准备数据集
给数据集重新命名
每一张图片前都插入图片的标签,可以使用ubuntu的批量重命名的功能.比如说我要做一个二分类的网络,命名格式应该是这样的: 其中每个图片的开头都是图片的标签,这样方便与生成图片txt
其中每个图片的开头都是图片的标签,这样方便与生成图片txt
新建两个文件夹用于存放数据集和验证集
训练集和测试集的图片比例为8:2,也就是说你一共有一百张图片,80张放入train文件夹里.20张放入val文件夹里

生成train.txt和val.txt用来保存图片名称和对应标签
新建一个python文件,命名为get_data.py
# -*- coding: UTF-8 -*-
import os
import re
path_train = #"train文件夹的路径" #建议是用绝对路径
path_val = #"val文件夹的路径"
path_txt = #"生成txt文件夹的路径"
if not os.path.exists(path_train):
print ("训练文件夹路径不存在!")
ox._exit()
else:
print ("成功加载训练文件夹")
if not os.path.exists(path_val):
print ("验证文件夹路径不存在!")
ox._exit()
else:
print ("成功加载验证文件夹")
file_train = open(path_txt + '/train.txt','wt')
file_val = open(path_txt + '/val.txt','wt')
file_train.truncate()
file_val.truncate()
pa = r".+(?=\.)"
pattern = re.compile(pa)
print ("正在生成train.txt")
for filename in os.listdir(path_train):
group_lable = pattern.search(filename)
str_label = str(group_lable.group())
if str_label[0]=='0':
train_lable = '0'
elif str_label[0]=='1':
train_lable = '1'
else:
print ("文件命名格式错误!")
ox._exit()
file_train.write(filename+' '+train_lable+'\n')
print ("成功生成train.txt")
print ("-----------------------------------")
print ("正在生成val.txt")
for filename in os.listdir(path_val):
group_lable = pattern.search(filename)
str_label = str(group_lable.group())
if str_label[0]=='0':
val_lable = '0'
elif str_label[0]=='1':
val_lable = '1'
else:
print ("文件命名格式错误!")
ox._exit()
file_val.write(filename+' '+val_lable+'\n')
print ("成功生成val.txt")
print ("退出程序")
然后运行脚本sudo python get_data.py
这样就生成了两个txt文件,如果你的脚本不报错,文件应该是长成这个样的.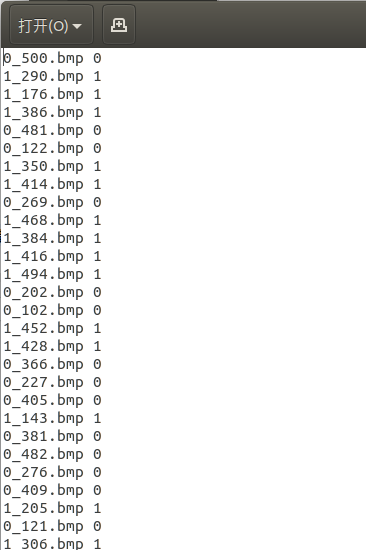
准备LMDB文件和均值文件
LMDB文件
我们要生成能让网络结构文件“读懂”的标签文件格式——lmdb,其实还有很多其它格式:leveldb、hdf5等等。那么我们是以哪种形式生成lmdb文件呢?用的是caffe提供的convert_imageset功能,让txt格式文件转换成lmdb格式
我们通过以下脚本实现转换: 需要改一下前两个路径
create_imagenet.sh
EXAMPLE=/home/peter/桌面/caffe自定义数据集 #工程的路径
TOOLS=/home/peter/桌面/caffeBuild/tools #caffe工具路径,一般是在caffe目录下的tools文件夹下
TRAIN_DATA_ROOT=$EXAMPLE/train/ #训练集路径
VAL_DATA_ROOT=$EXAMPLE/val/ #测试集路径
RESIZE=true #这里是resize图片,我这里时开启此功能,resize成20*20
if $RESIZE; then
RESIZE_HEIGHT=20
RESIZE_WIDTH=20
else
RESIZE_HEIGHT=0
RESIZE_WIDTH=0
fi
if [ ! -d "$TRAIN_DATA_ROOT" ]; then
echo "Error: 训练集路径错误: $TRAIN_DATA_ROOT"
echo "Set the TRAIN_DATA_ROOT variable in create_imagenet.sh to the path" \
"where the ImageNet training data is stored."
exit 1
fi
if [ ! -d "$VAL_DATA_ROOT" ]; then
echo "Error: 验证集路径错误: $VAL_DATA_ROOT"
echo "Set the VAL_DATA_ROOT variable in create_imagenet.sh to the path" \
"where the ImageNet validation data is stored."
exit 1
fi
#生成前需要先删除已有的文件夹 必须,不然会报错
rm -rf $EXAMPLE/train_lmdb
rm -rf $EXAMPLE/val_lmdb
echo "删除已有的lmdb文件夹"
#训练_lmdb
echo "生成训练lmdb"
GLOG_logtostderr=1 $TOOLS/convert_imageset \
--resize_height=$RESIZE_HEIGHT \
--resize_width=$RESIZE_WIDTH \
--shuffle \
$TRAIN_DATA_ROOT \
$EXAMPLE/train.txt \
$EXAMPLE/train_lmdb
#生成的训练lmdb文件所在文件夹,注意train_lmdb是文件夹名称
#测试_lmdb
echo "生成测试lmdb"
GLOG_logtostderr=1 $TOOLS/convert_imageset \
--resize_height=$RESIZE_HEIGHT \
--resize_width=$RESIZE_WIDTH \
--shuffle \
$VAL_DATA_ROOT \
$EXAMPLE/val.txt \
$EXAMPLE/val_lmdb
#生成的测试lmdb文件所在文件夹,注意val_lmdb文件夹名称
#解锁生成的文件夹
echo "解锁lmdb文件夹"
chmod -R 777 $EXAMPLE/train_lmdb
chmod -R 777 $EXAMPLE/val_lmdb
echo "完成"
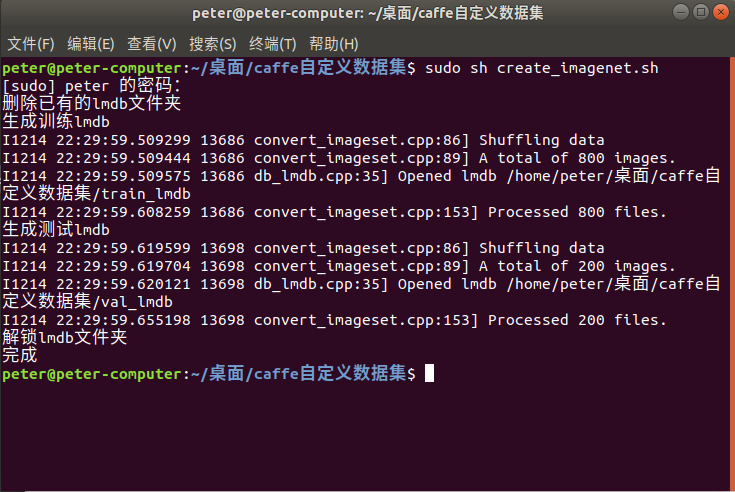
保存退出然后运行sudo sh create_imagenet.sh
脚本正常运行完之后应该是这个样子的,如果有报错多半是你的路径填的不对,仔细检查一下.
均值文件
生成均值文件的脚本比较简单,路径都可以从上一个脚本复制过来
compute_image_mean.sh
EXAMPLE=/home/peter/桌面/caffe自定义数据集 #工程的路径
TOOLS=/home/peter/桌面/caffeBuild/tools #caffe工具路径
$TOOLS/compute_image_mean $EXAMPLE/train_lmdb \
$EXAMPLE/train_mean.binaryproto
$TOOLS/compute_image_mean $EXAMPLE/val_lmdb \
$EXAMPLE/val_mean.binaryproto
echo "完成"
脚本运行完成后应该生成了一个这样的文件
准备网络结构文件和训练文件
这个文件,是网络的结构文件,一般说设计网络,狭义上就是指的设计这个文件的内容,对于初学者,我建议你们先用简单的模板训练,在看懂的基础上,了解这个文件的结构,以及自己如何去设计这个文件。
caffe自带的demo中有很简单的,也很经典的LeNet、AlexNet、GoogLeNet模型(google为了向经典的LeNet致敬,才将L大写),再次强烈建议大家将这些模型的结构看一遍,弄懂为何这样设计,这对你以后自己去设计网络有很大的启发,当然基本的数理统计算法,比如经典的BP算法、autoencoder、基本的激活函数sigmoid函数LRN函数等等,这些需要根据格个人情况自行补课。
这里给出了一个简单的网络结构文件.只需要更改一下路径和一些简单的信息即可使用
在工程目录下新建一个make_model文件夹,在文件夹中新建一些文档
train_val.prototxt
这个文件需要改一些训练集的路径和最后输出的分类数量
name: "LeNet"
layer {
name: "mnist"
type: "Data"
top: "data"
top: "label"
include {
phase: TRAIN
}
transform_param {
mirror: true
crop_size: 20
mean_file: "/home/peter/桌面/caffe自定义数据集/train_mean.binaryproto" #均值文件的路径
}
data_param {
source: "/home/peter/桌面/caffe自定义数据集/train_lmdb" #训练LMDB的路径
batch_size: 32
backend: LMDB
}
}
layer {
name: "mnist"
type: "Data"
top: "data"
top: "label"
include {
phase: TEST
}
transform_param {
mirror: false
crop_size: 20
mean_file: "/home/peter/桌面/caffe自定义数据集/val_mean.binaryproto" #均值文件的路径
}
data_param {
source: "/home/peter/桌面/caffe自定义数据集/val_lmdb" #验证LMDB的路径
batch_size: 50
backend: LMDB
}
}
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 20
kernel_size: 5
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "conv2"
type: "Convolution"
bottom: "pool1"
top: "conv2"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 50
kernel_size: 5
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "pool2"
type: "Pooling"
bottom: "conv2"
top: "pool2"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "fc1"
type: "InnerProduct"
bottom: "pool2"
top: "ip1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
inner_product_param {
num_output: 500
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "relu1"
type: "ReLU"
bottom: "ip1"
top: "ip1"
}
layer {
name: "ip2"
type: "InnerProduct"
bottom: "ip1"
top: "ip2"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
inner_product_param {
num_output: 2 #最后输出的分类数量,我这里是二分类,所以写2
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "loss"
type: "Softmax"
bottom: "ip2"
top: "loss"
}
solver.prototxt
这个文件就是配置一下训练时的规则,这个文件里面的参数也是模型质量的关键。
net: "/home/peter/桌面/caffe自定义数据集/make_model/train_val.prototxt" #这里时train_val.prototxt文件的路径
test_iter: 8 # x * 50 = 训练集大小
test_interval: 50
base_lr: 0.01
lr_policy: "step"
gamma: 0.1
stepsize: 100
display: 20
max_iter: 100 #最大训练次数
momentum: 0.9
weight_decay: 0.0005
snapshot: 20 #每50次保存一次模型快照
snapshot_prefix: "/home/peter/桌面/caffe自定义数据集/save_model/" #生成快照的路径
solver_mode: CPU
deploy.prototxt
这个文件是根据train_val.prototxt编写的,里面结构大体一样,只是把训练的参数去掉。
这个文件我们只需要修改一处,将输出的类别改为2
name: "LeNet"
layer {
name: "data"
type: "Input"
top: "data"
input_param { shape: { dim: 1 dim: 3 dim: 20 dim: 20} }
}
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 20
kernel_size: 5
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "conv2"
type: "Convolution"
bottom: "pool1"
top: "conv2"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 50
kernel_size: 5
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "pool2"
type: "Pooling"
bottom: "conv2"
top: "pool2"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "fc1"
type: "InnerProduct"
bottom: "pool2"
top: "ip1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
inner_product_param {
num_output: 500
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "relu1"
type: "ReLU"
bottom: "ip1"
top: "ip1"
}
layer {
name: "ip2"
type: "InnerProduct"
bottom: "ip1"
top: "ip2"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
inner_product_param {
num_output: 2 #最后的分类数量
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "loss"
type: "Softmax"
bottom: "ip2"
top: "loss"
}
至此,三个网络文件已经准备好了,下一步就是开始训练了.
开始训练
新建一个脚本来训练网络 caffe_train.sh
EXAMPLE=/home/peter/桌面/caffe自定义数据集 #工程的路径
caffe train --solver=$EXAMPLE/make_model/solver.prototxt
chmod -R 777 $EXAMPLE/save_model
echo "完成"
如果你的路径填的都是对的,你会在工程目录的save_model文件夹下看到caffe训练出来的模型