DLIP | 一个简单高效的蒸馏视觉-语言预训练框架
参考源于:DLIP: Distilling Language-Image Pre-training (单位:厦门大学,字节跳动)
前情提要
Vision-Language Pre-training (VLP) 在极其庞大的参数辅助下取得了显著的进展, 但大参数量带来的部署和执行为落地带来了困难
动机
知识蒸馏被广泛认为是模型压缩中的关键步骤, 作者希望给出了关于蒸馏轻量级但性能良好的VLP模型。
挑战
(1) VLP模型的架构通常包含多个模块,包括图像编码器 (例如,ViT)、文本编码器 (例如,BERT)、多模态融合模块或任务解码器。因此,确定可以进行蒸馏的模块是一个非常复杂的任务
(2) 与单模态 (只有图像或语言) 蒸馏相比,VLP模型涉及多种信息传递,包括单模态信息 (例如,视觉信息) 和多模态融合信息 (例如,视觉-语言信息) 。因此,有必要研究不同信息传递对蒸馏中下游任务的影响
验证实验
作者进行了一系列的对比实验,以深入研究和分析VLP模型。作者对不同模块压缩的作用进行了消融实验,并追求最小的变化,以确定VLP蒸馏中不同模态信息传递的影响。通过广泛的分析,作者总结了以下发现:
(1) 在模块的层面上,图像编码器和文本编码器在模型压缩中具有同等重要性。此外,大型融合模块是不必要的,适度的融合层是有益且高效的
(2) 对于带有解码器的VLP模型,解码器需要单独进行蒸馏,以提高基于解码器的下游任务的性能
(3) 使用预训练模型进行初始化对于视觉编码器非常重要,但对文本编码器的影响较小
作者提出 DLIP: 一个简单高效的蒸馏视觉-语言预训练框架
模型整体框架
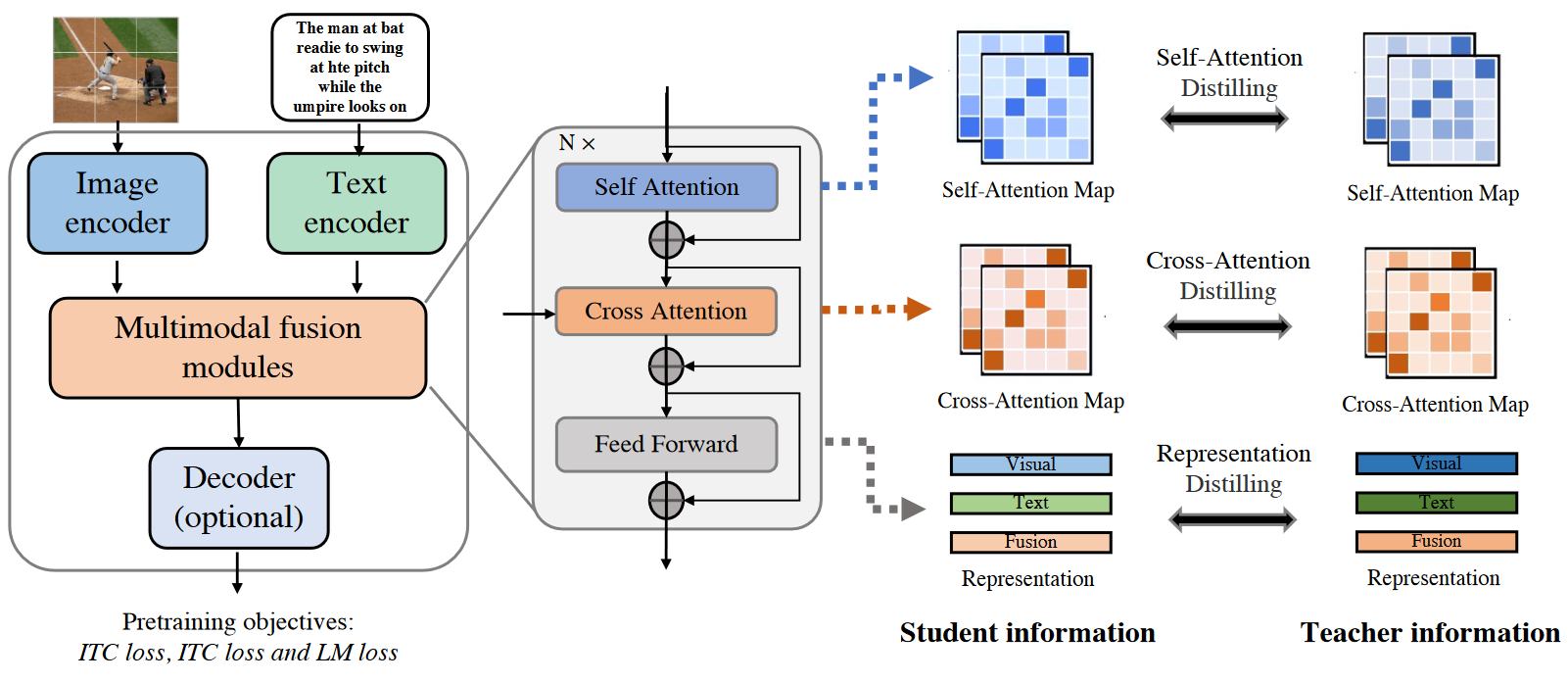
一个完全基于Transformer的VLP模型通常由几个重要模块组成,包括图像编码器、文本编码器、多模态融合模块和任务编码器,如上图所示。给定一个图像-文本对,VLP模型首先通过图像编码器和文本编码器提取出视觉表示序列和文本表示序列。然后,视觉和文本表示被输入到一个多模态融合模块中,以生成跨模态表示。这些表示可以选择性地被送入任务解码器,然后生成最终的输出。
预训练
作者引入了三个流行的目标函数:
(1) 图像-文本对比 Image-Text Contrastive (ITC) 损失:损失的目标是通过鼓励正向图像-文本对在表示空间中具有相似的表示,与负向对形成对比
(2) 图像-文本匹配 Image-Text Matching (ITM) 损失:损失的目标是学习一种图像-文本多模态表示,能够捕捉视觉和语言之间的细粒度对齐关系
(3) 语言建模 Language Modeling (LM) 损失:损失的目标是在给定图像的情况下生成文本描述
蒸馏
作者从隐藏表示和注意力信息传递的角度设计了多个蒸馏目标
(1) Representation Distillation Loss:对于隐藏表示信息的传递,先前的研究表明隐藏表示的对齐是一种有效的蒸馏策略,可以高效地从教师模型中学习信息。因此,作者使用隐藏表示蒸馏来最小化隐藏表示之间的差异,损失值如图所示
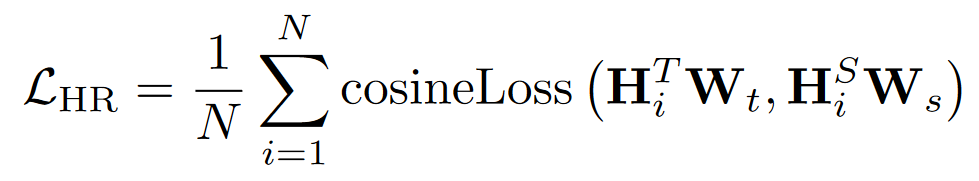
其中,N 表示Transformer的层数, $W_s$ 和 $W_t$ 是可学习的线性变换,将教师模型和学生模型的表示映射到相同的维度空间。作者考虑了三种隐藏表示用于模态信息传递:视觉表示、文本表示和融合表示。
(2) Attention-Based Distillation Loss:一些研究表明,预训练语言模型的自注意力分布捕捉到了丰富的语言信息层次结构。在先前的工作中,将自注意力分布进行传递用于Transformer蒸馏,通过优化教师模型和学生模型的注意力分布之间的KL散度来实现,损失如图所示:
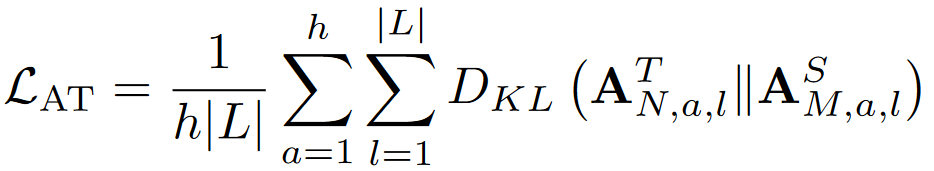
其中,L和h表示序列长度和注意力头的数量, N和M分别表示教师模型和学生模型的层数, ${A_N}^T$和${A_M}^S$分别表示教师模型的第N层和学生模型的第M层的注意力分布。
(3) 最后,作者将预训练目标与蒸馏目标相结合。DLIP的总体目标可以表述如下