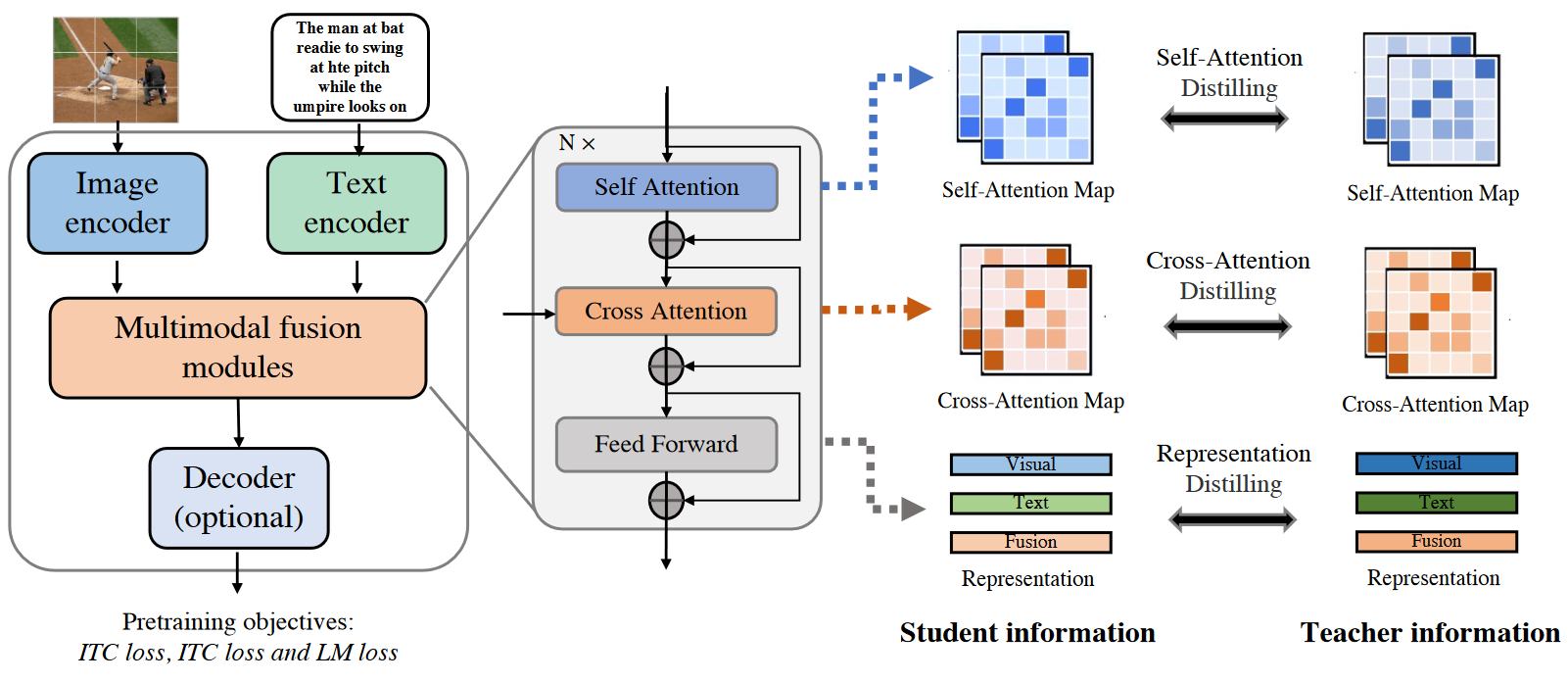
多模态医疗数据分析
图-图跨模态
参考源于:图像多模态医疗数据综述
在同一个样本形态体系下,一般采取模态融合的形式进行模态信息的利用。根据多模态融合策略,我们将网络结构分为输入级特征融合、层融合网络和决策融合网络,对于每一种融合策略,我们总结了一些常用的方法,如图所示:

其中,在输入级融合图像特征,是目前最主流的应用方式,如图所示:

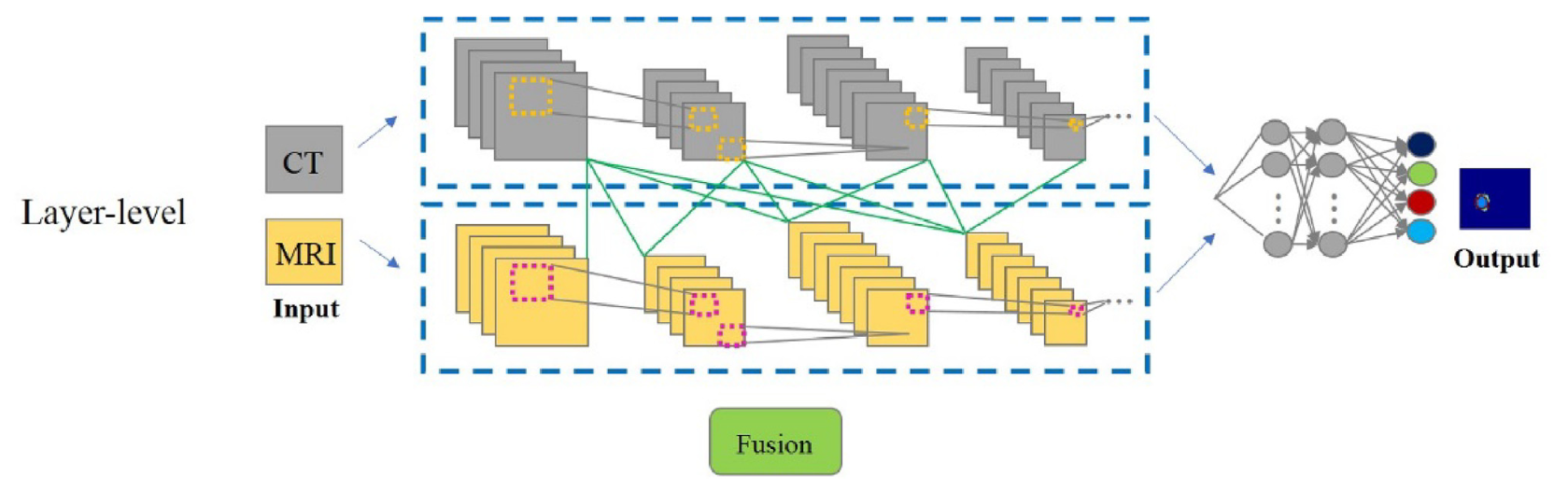
而层级融合网络,则是一种在模型内部融合多模态特征的方式,主要集中与编码过程中进行特征融合。在模态特征相差不大的情况下,该类型融合网络可以有效地互补图像特征,保证更好的分割结果:
在决策融合分割网络中,与层级融合一样,将每个模态图像作为单个分割网络的单一输入。与层级融合网络有部分差别的是,该类型融合网络主要在决策层面进行信息交互,在编码过程中几乎不发生交流,各个模态经历独自编码过程。但是,该类型网络面对统计特征分布不均的多模态数据具有奇效,可以通过决策投票(或其他类型决策)的方式汇总多个模态的信息,从而得出泛化性能较好的决策结果:
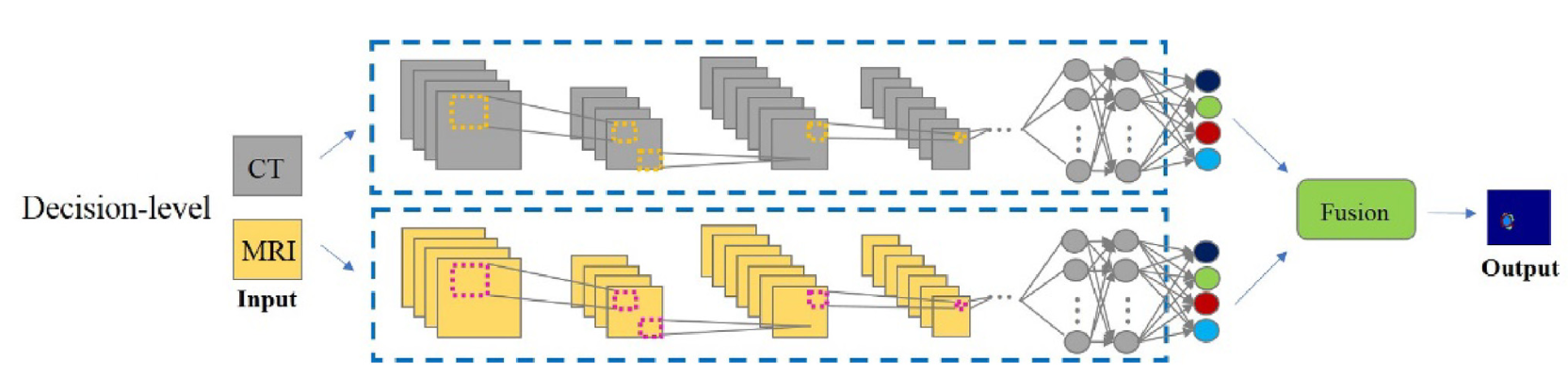
图-文跨模态
参考源于:MedCLIP: Contrastive Learning from Unpaired Medical Images and Text
医疗图像难以实现跨模态信息共享,不能直接套用CLIP的原因主要如图所示:
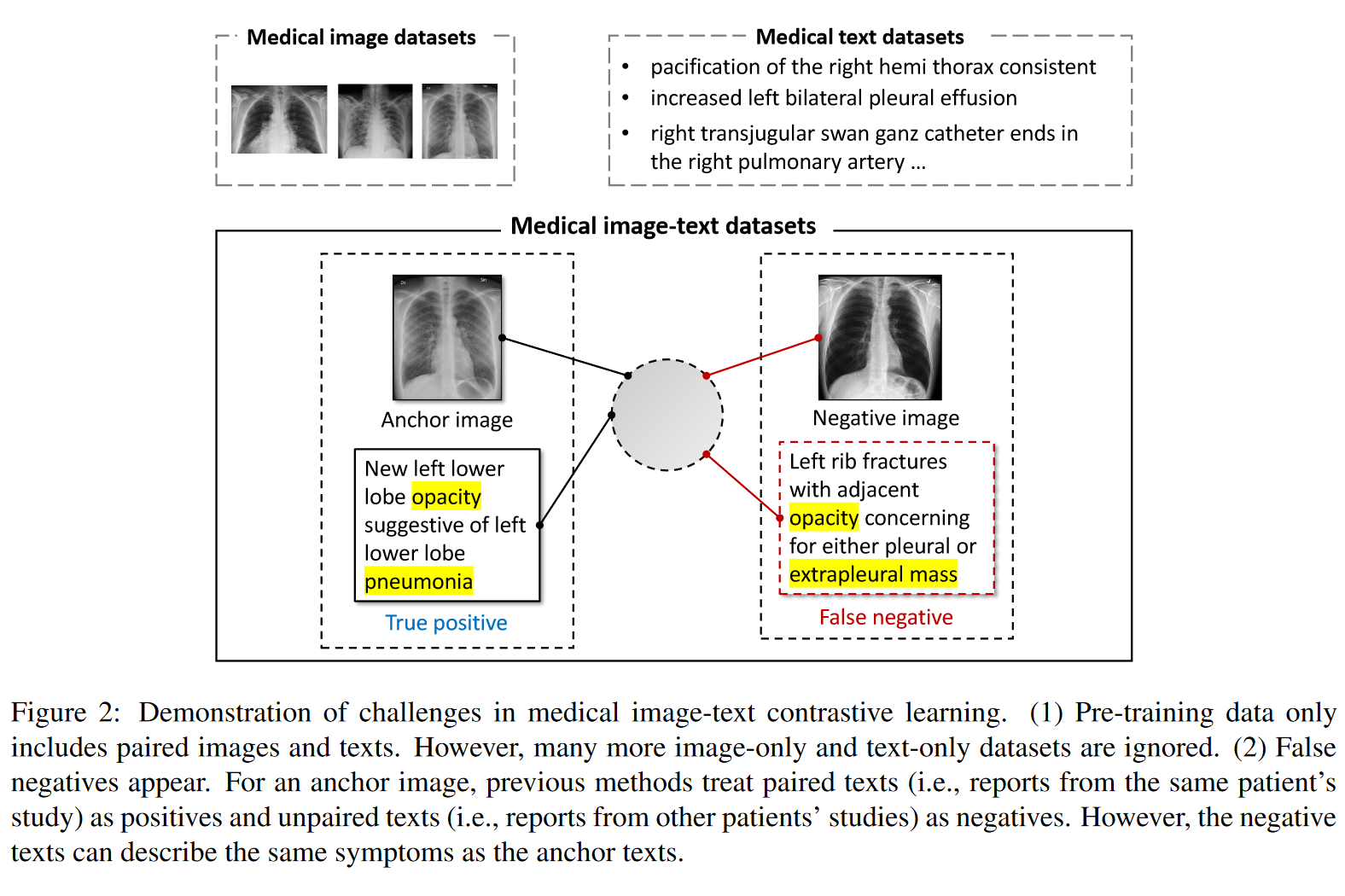
问题主要集中于:
(1) 成对的病例图像-检测报告文本非常稀少,根本不足以支撑大规模预训练
(2) 出现假阴性。对于锚定图像,以往的方法将成对文本(即来自同一患者的研究报告)视为正例,未成对文本(即来自其他患者研究的报道)视为负例。然而,负例文本可以描述与锚文本相同的症状。这种情况的出现是因为不同病例表现有可能是相近的,这导致文本描述也可能是相似的,这就造成对齐困难。
如何解决?
本文尝试切入一个全新角度,即利用解耦图像和文本进行对比学习,同时,利用更加深入的医学知识消除假阳性。
具体来讲,方法如下:
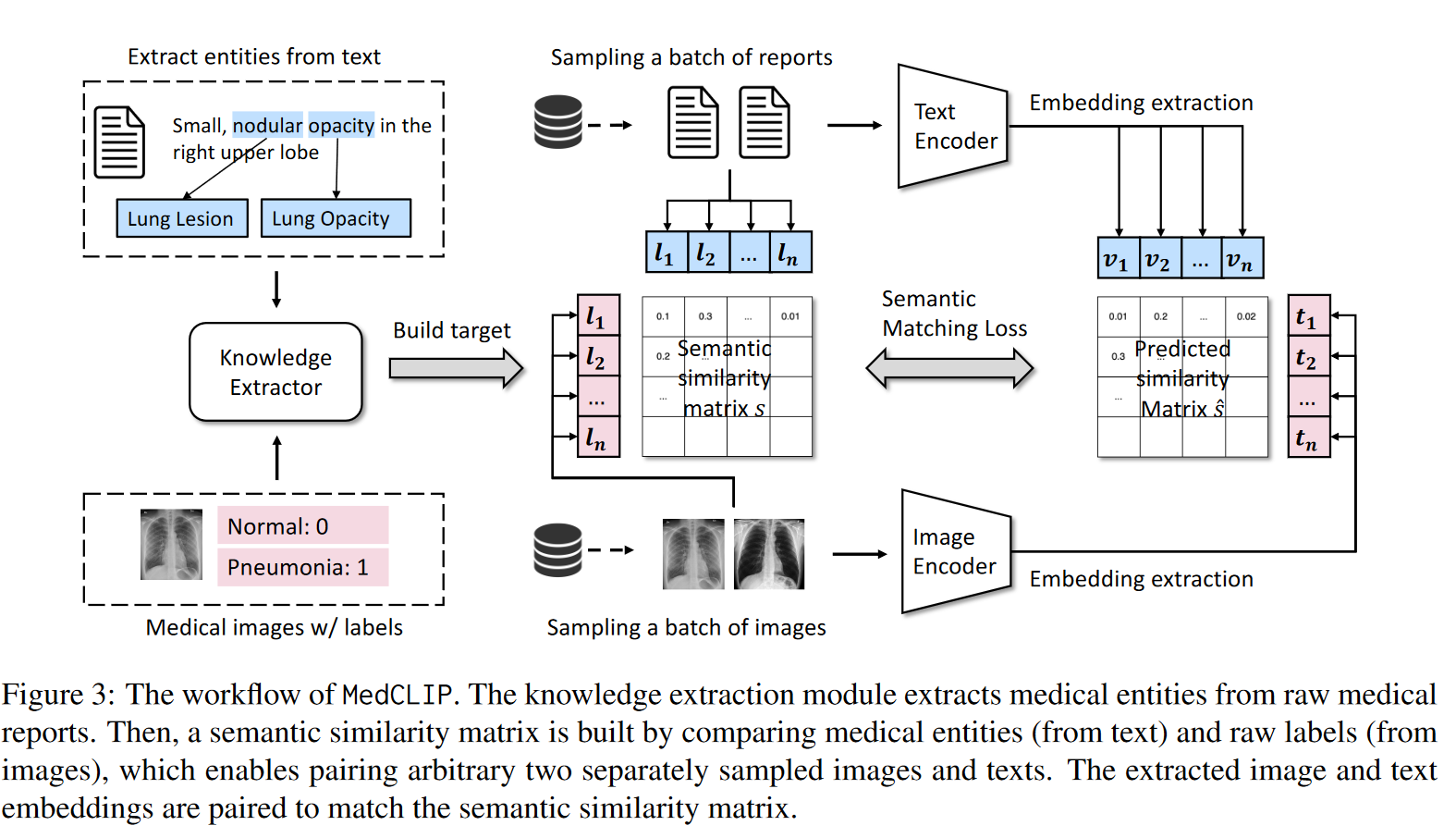
(1) 构建语义相似度矩阵的知识抽取:构建一个知识抽取模块,从原始医疗报告中抽取医疗实体词,参考MetaMap 医疗文本提取系统。然后,通过比较医学实体(来自文本)和原始标签(来自图像)构建语义相似度矩阵实义标签,即基于实义文本对图像进行解耦。然后,基于相似度矩阵实义标签,首先对未配对的图-文样本进行一次相似度计算,得出矩阵1。
(2) 提取嵌入的视觉和文本编码器:与CLIP类似,该方法同步构建两类编码器,并接受图文数据编码。接受图文数据并编码后,利用编码数据计算相似度矩阵2。
(3) 训练整个模型的语义匹配损失:通过构建的语义标签来桥接图像和文本。基于医学知识构建相似度软标签(此处必须结合一定专家知识),比对编码前的相似度矩阵和编码后的相似度矩阵,计算语义匹配损失,回传更新视觉与文本编码器
整个流程的具体逻辑为:我有n个配对好的图-文样本,另m个图样本(无配对文),h个文样本(无配对图)。以往,编码器只对这n个配对好的图-文样本作用。但此时,如果我们先利用这n个配对好的图-文样本进行语义相似度矩阵标签的构建(知识抽取模块),在过编码器前先基于实义语义相似度对齐,得出一个相似度矩阵;然后再利用编码器对另外m个图样本和h个文样本进行编码,基于编码结果和实义语义再构建一次相似度矩阵,然后比对两个矩阵得出匹配效果优劣损失,回传更新编码器,即可以利用( n x m ) x ( n x h )组数据样本。