AI翻唱?有手就行!
AI翻唱?有手就行!
AI 翻唱本质上是训练一个音色模型RVC模型,而后将音色替换现有曲目的过程。因此,本过程的实现需要分为两部分:RVC模型训练、现有歌曲翻唱
RVC模型训练
RVC模型的训练,此处可以借助开源项目 RVC-WebUI 进行训练。
进入代码仓库后,下载项目,置于训练环境中。(此处笔者放在Linux服务器环境中,如果使用win或者mac该项目中有详解)
在N卡环境中,基于以下命令准备训练环境
1 | pip install -r requirements.txt |
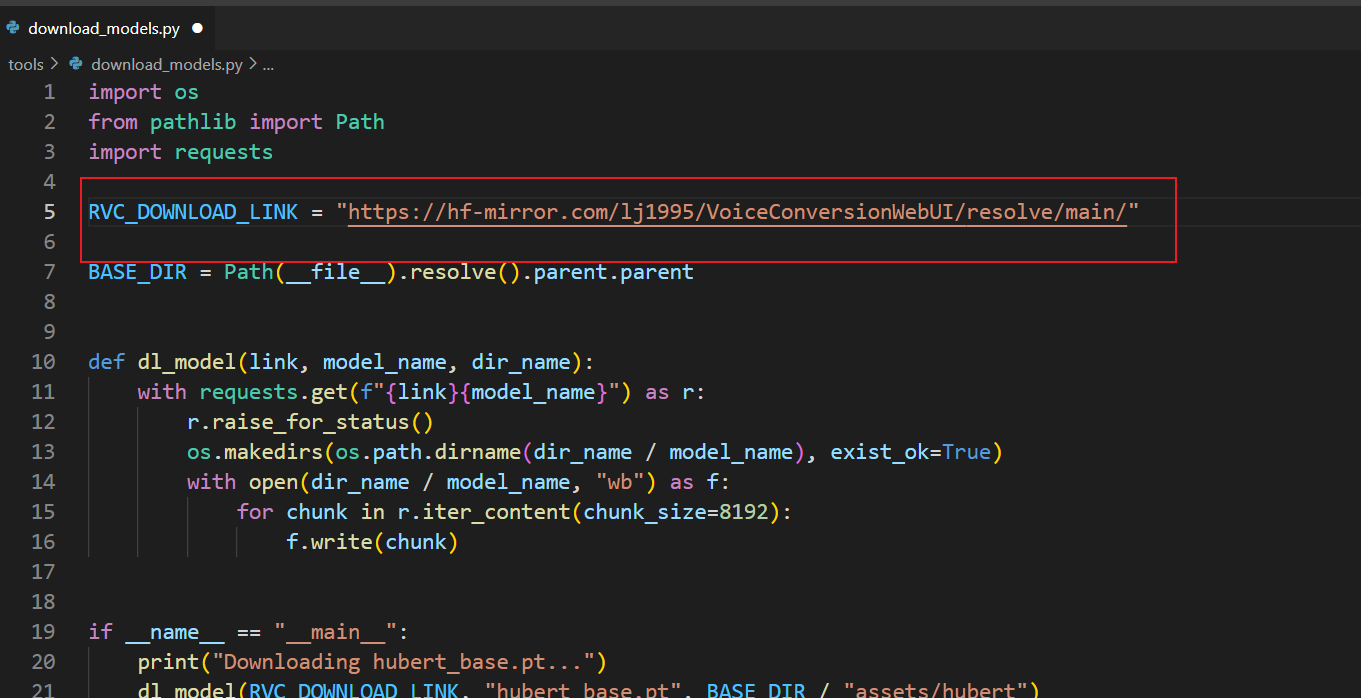
预训练模型下载:
在项目文件 .tools/download_models.py中改写一句话:用于为非VPN服务器更改下载路径。修改后,可以使用以下命令下载所有所需预训练模型
1 | python3 /tools/download_models.py |

安装 ffmpeg:
Ubuntu/Debian 用户可以直接通过以下命令执行下载:
1 | sudo apt install ffmpeg |

下载 rmvpe 人声音高提取算法所需文件
如果想使用最新的RMVPE人声音高提取算法,则需要下载音高提取模型参数并放置于RVC根目录
完成上诉步骤后,既可以开始使用,终端输入以下命令,直接打开web执行界面,如果无反应则转发端口。
1 | python infer-web.py |
训练RVC模型(个人测试在多卡环境中可能导致训练错误,因此此处介绍单卡训练),以下为使用教程
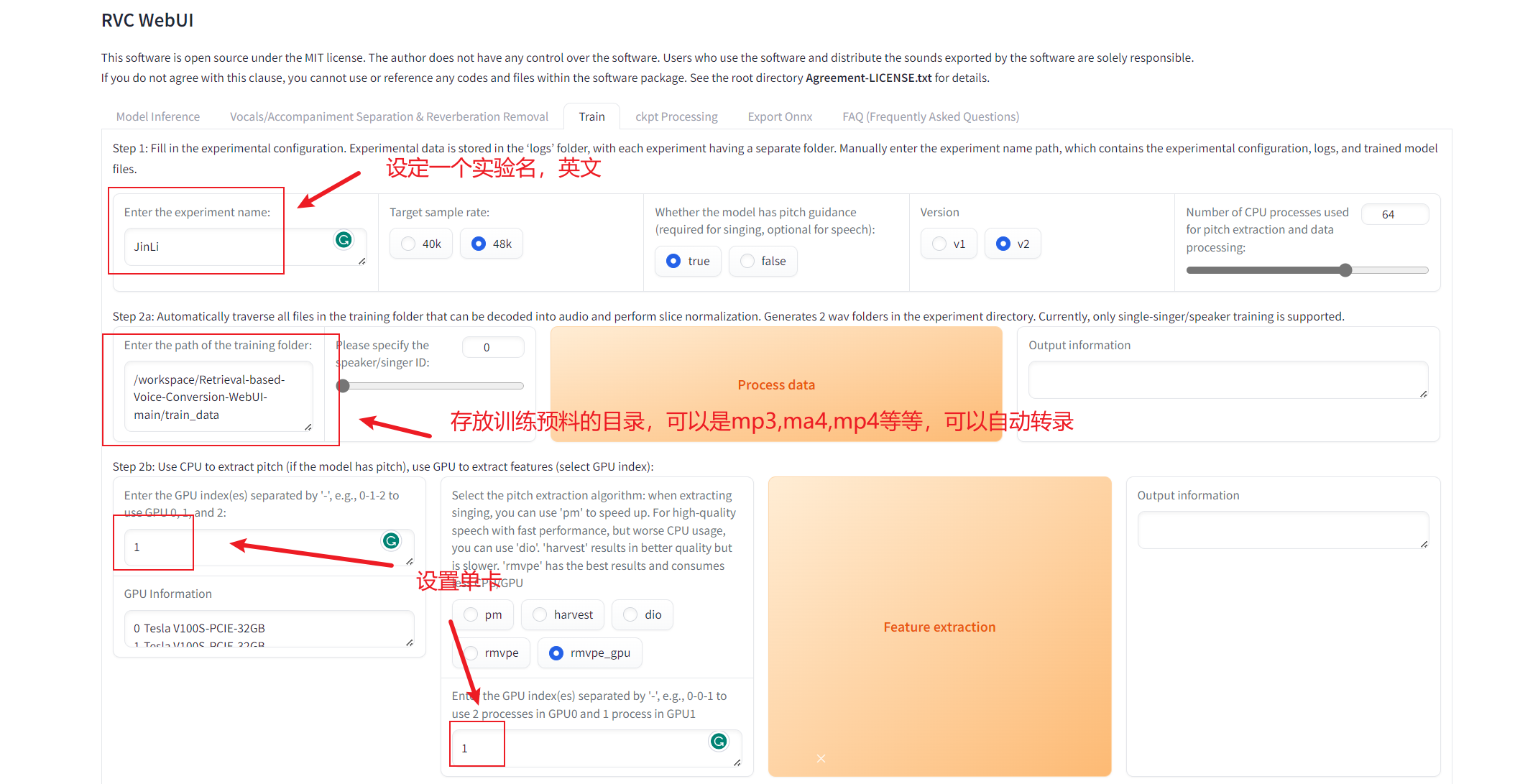
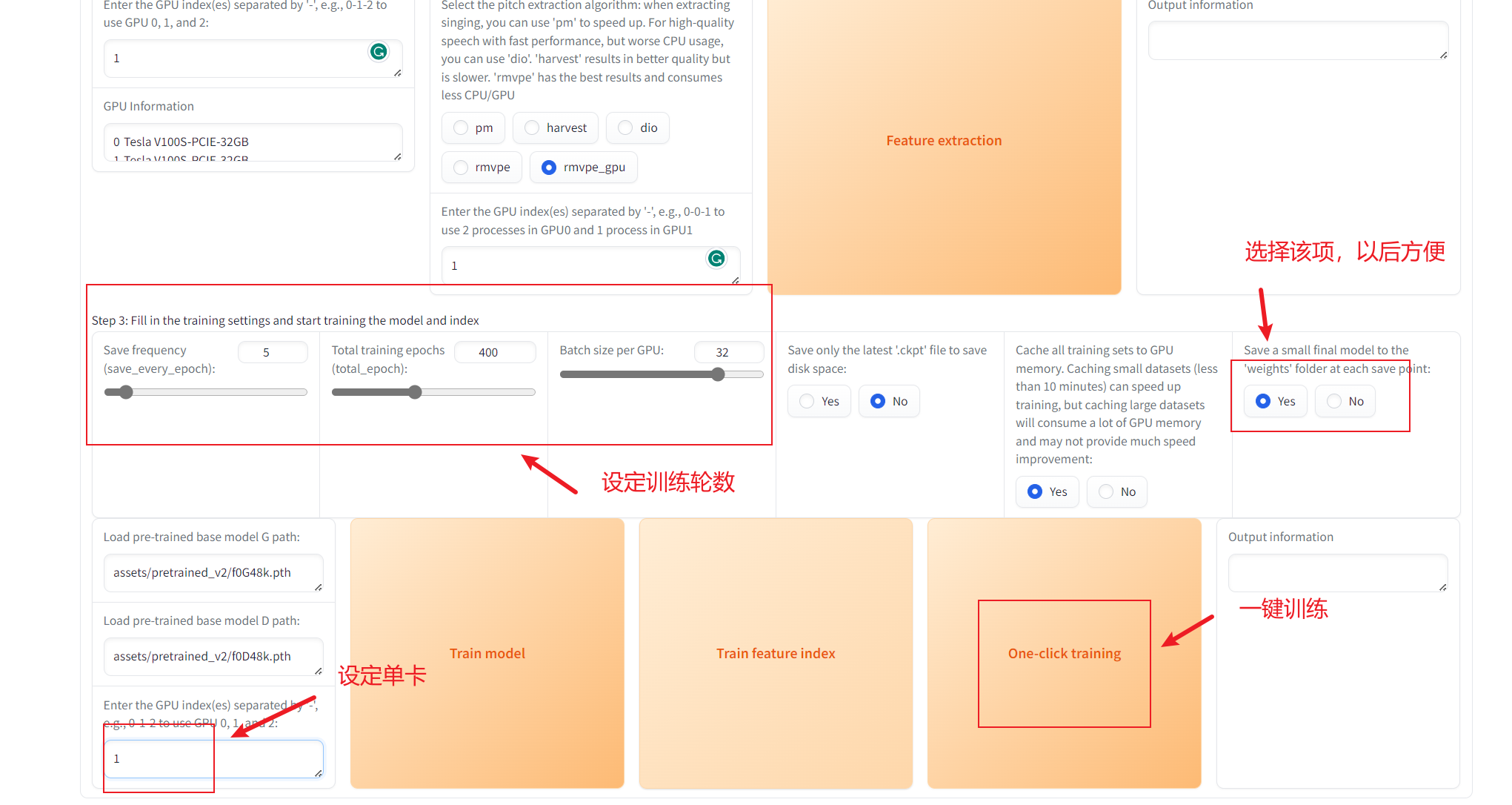
一键训练后,可以在工程目录 assets/weights 中找到对应实验名的.pth文件,该文件就是训练好的因素文件。
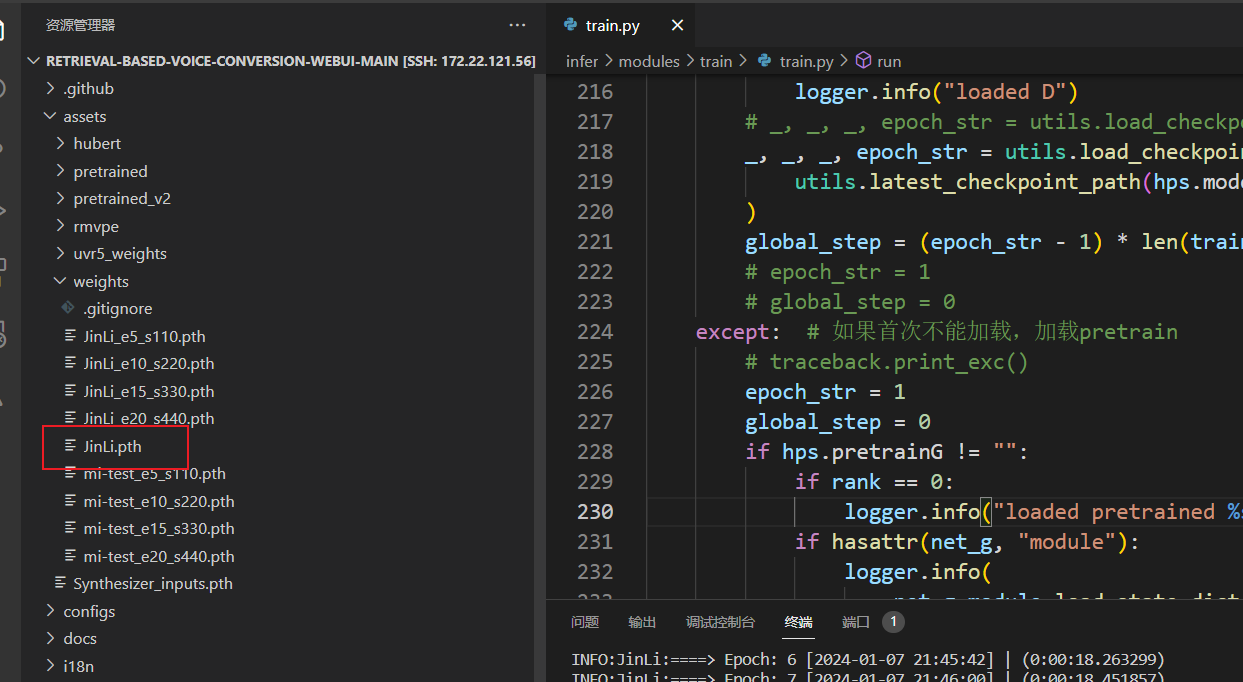
现有歌曲翻唱
对现有歌曲进行翻唱,可以使用 Replay 软件。安装完成后界面如下:
下载想要翻唱的歌曲.mp3,可以在 此处 下载。然后导入训练好的RVC模型.pth,然后直接生成即可。
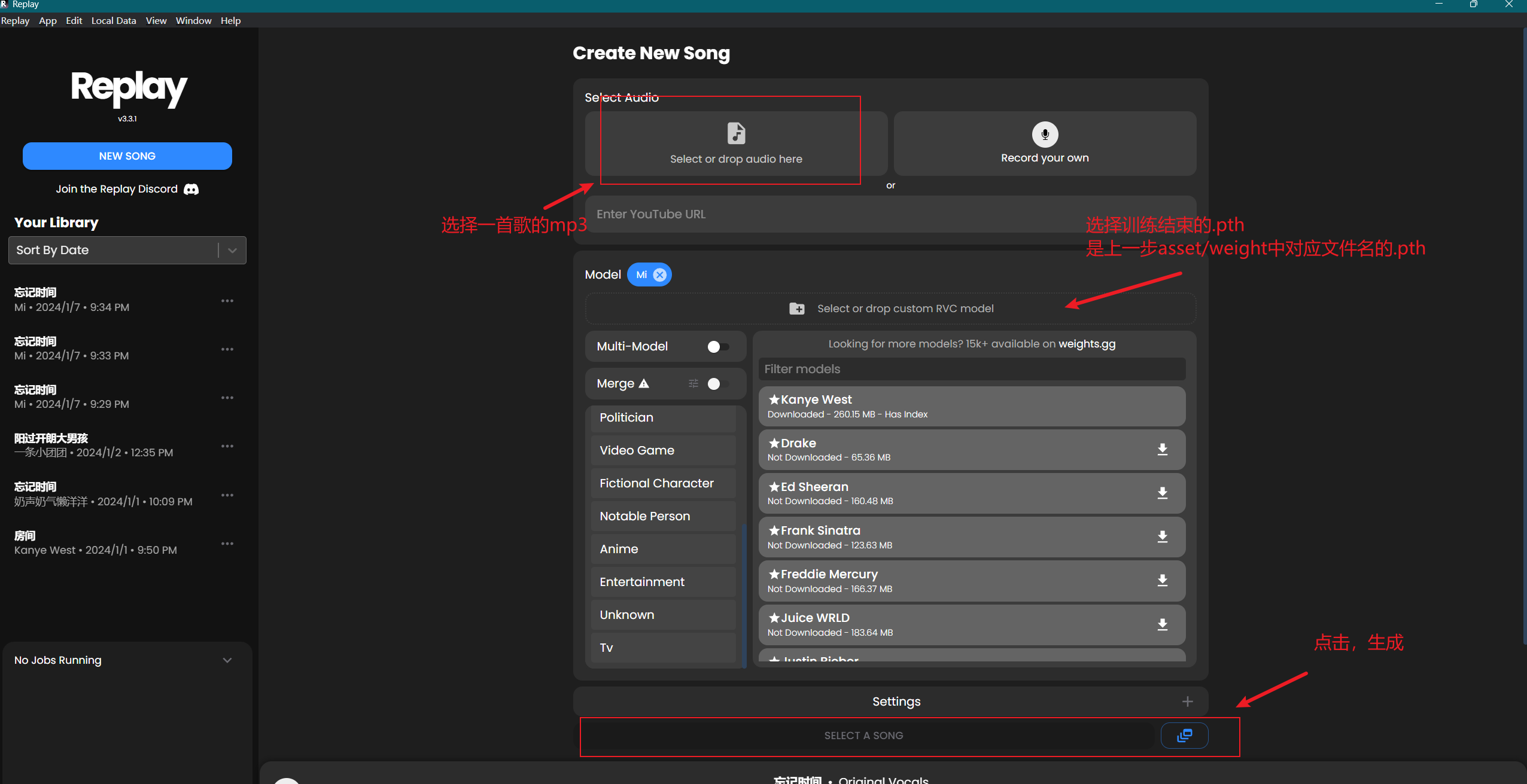
另外,该软件有现成模型,可供自行使用,可玩性max。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 科研就像坟头蹦迪, 越蹦越嗨!
评论